 M3CoT
M3CoT
Multi-modal Chain-of-Thought (MCoT) requires models to leverage knowledge from both textual and visual
modalities for step-by-step reasoning, which gains increasing attention.
Nevertheless, the current MCoT benchmark still faces some challenges: (1) absence of visual modal
reasoning, (2) single-step visual modal reasoning, and (3) Domain missing, thereby
hindering the development of MCoT.
Motivated by this, we introduce a novel benchmark (M3CoT) to address the above
challenges,
advancing the multi-domain, multi-step, and multi-modal CoT.
Additionally, we conduct a thorough evaluation involving abundant MCoT approaches on Vision Large Language
Models (VLLMs).
In addition, we highlight that the current VLLMs still struggle to correctly reason in
M3CoT and there is a large gap between VLLMs and human performance in
M3CoT, despite their superior results on previous MCoT benchmarks.
To our knowledge, we take the first meaningful step toward the multi-domain, multi-step, and multi-modal
scenario in MCoT.
We hope that M3CoT will serve as a valuable
resource, providing a pioneering foundation in multi-domain, multi-step, multi-modal chain-of-thought
research.
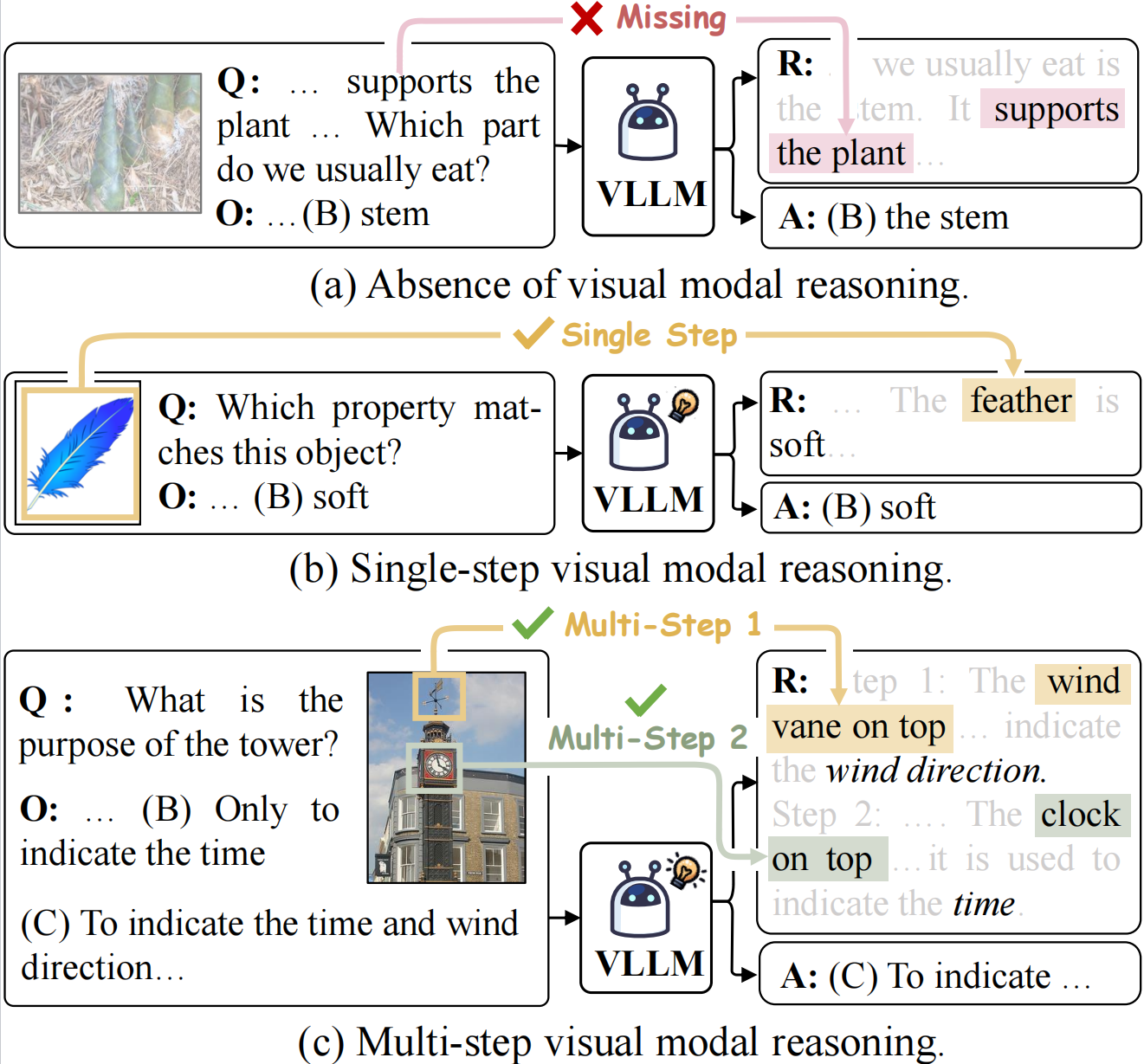
We find that the existing benchmarks exhibit three major drawbacks:
Absence of visual modal reasoning As shown in Figure a, the model can successfully produce rationale and answer solely based on the textual modality context of "supports the plant", which cannot truly reflect the ability of multi-modal CoT model.
Single-step visual modal reasoning As illustrated in Figure b, the model only requires a single-step "feather" object to predict the correct rationale and answer, which cannot be satisfied in the complex multi-step CoT scenario.
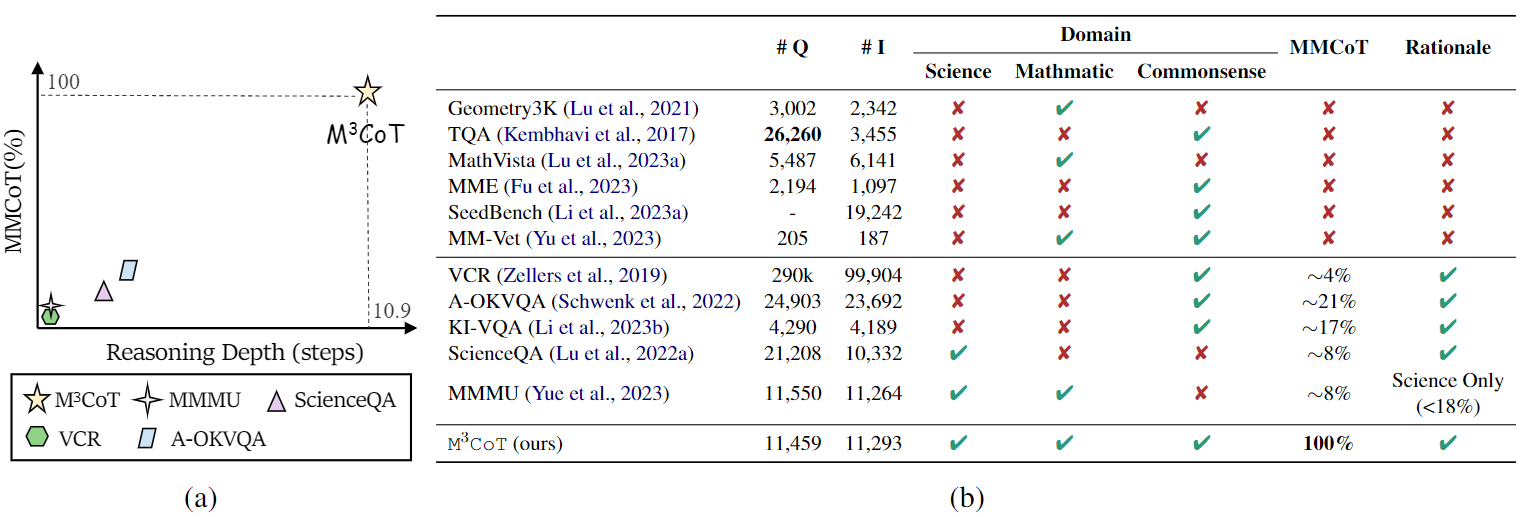
Domain Missing Commonsense and mathematics are important domains for evaluating multi-modal CoT, but the current benchmarks lack these topics, hindering the comprehensive evaluation progress of multi-modal CoT.
For more details, you can explore the datatset and check the visualizations here: Explore and Visualizations.
Our dataset is distributed under the CC BY-NC-SA (Attribution-NonCommercial-ShareAlike) license. You can download our dataset from M3CoT (Google Drive), or check out our github repository.
💡 The M3CoT dataset is now available at HuggingFace Datasets!
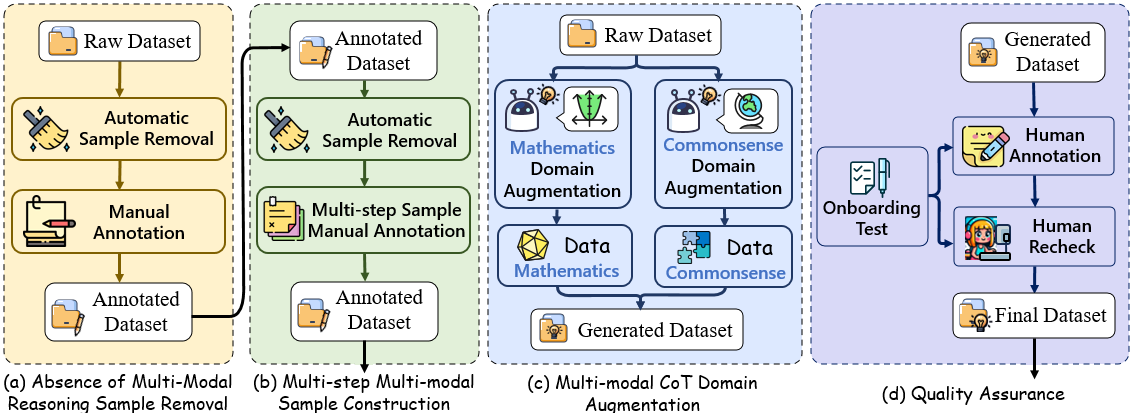
Specifically, to address the first issue, we directly remove samples that could infer the final answer without the need for images.
To tackle the second issue, we manually annotate and select multi-step multi-modal samples. Specifically, we provide expert annotators with textual context and rationales without images. Experts were required to determine when multi-step reasoning could not be resolved solely based on textual context. Subsequently, we present the images to experts to ascertain whether multi-step reasoning occurred across textual and visual modalities.
To solve the third issue, we explore LLM-guided augmentation to synthesize the multi-step MCoT data for commonsense and mathematics domains.
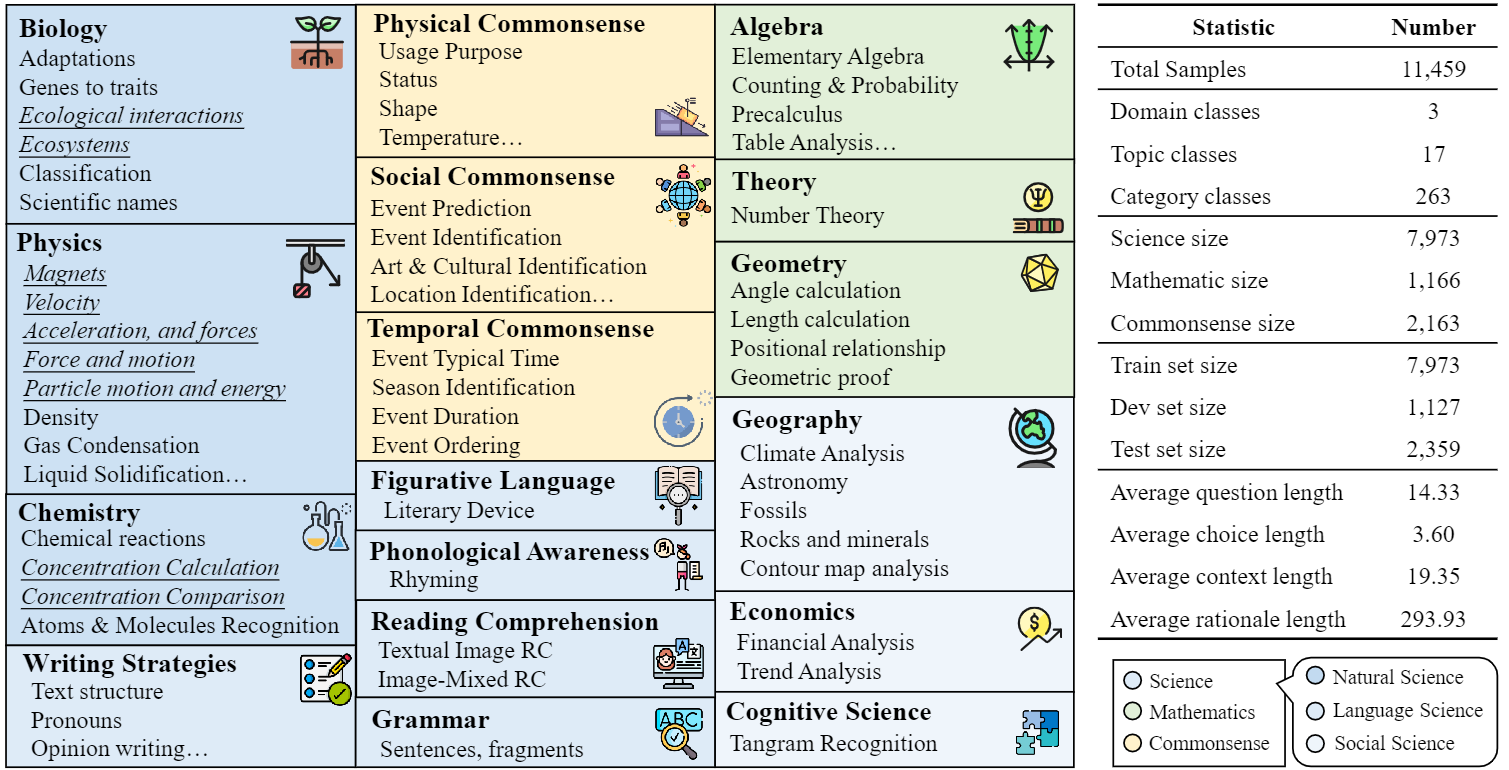
M3CoT is randomly divided into three splits: train, validation, and test splits,
containing 7,973, 1,127, and 2,359 examples respectively.
Compared to ScienceQA, M3CoT demands more intricate reasoning, with an average
length of 293.93, much higher than ScienceQA's 47.66.
We evaluate various VLLMs in M3CoT, including Kosmos-2,
InstructBLIP, LLaVA-V1.5, CogVLM, Gemini, GPT4V. In addition,
we explore some prompting strategies. Specifically, we utilize Direct approach to submitting
samples in the VLLMs required format; CoT with “Let’s think step-by-step!”; Desp–CoT
with an initial image description prompting; CCoT with better description in graph format.
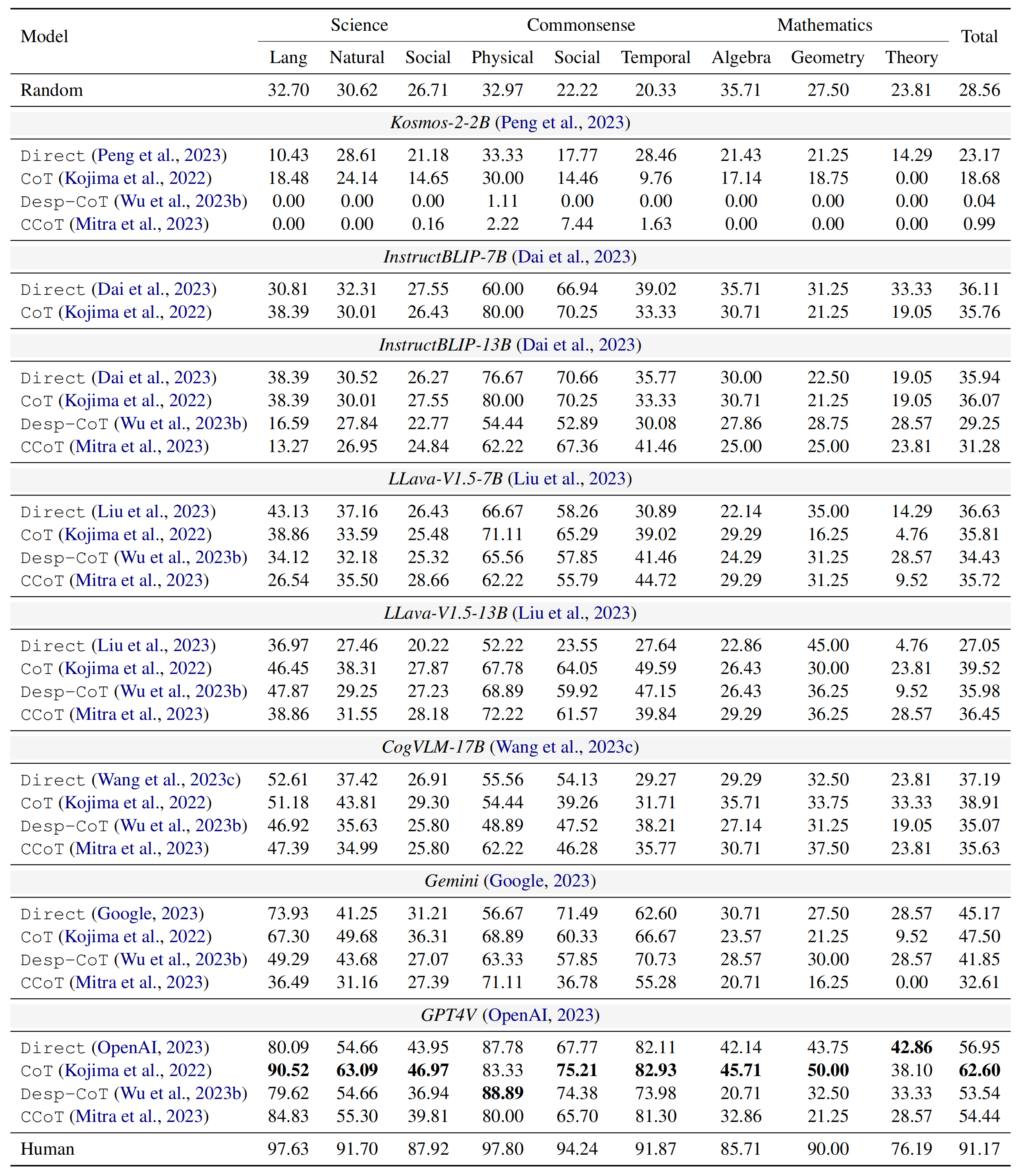
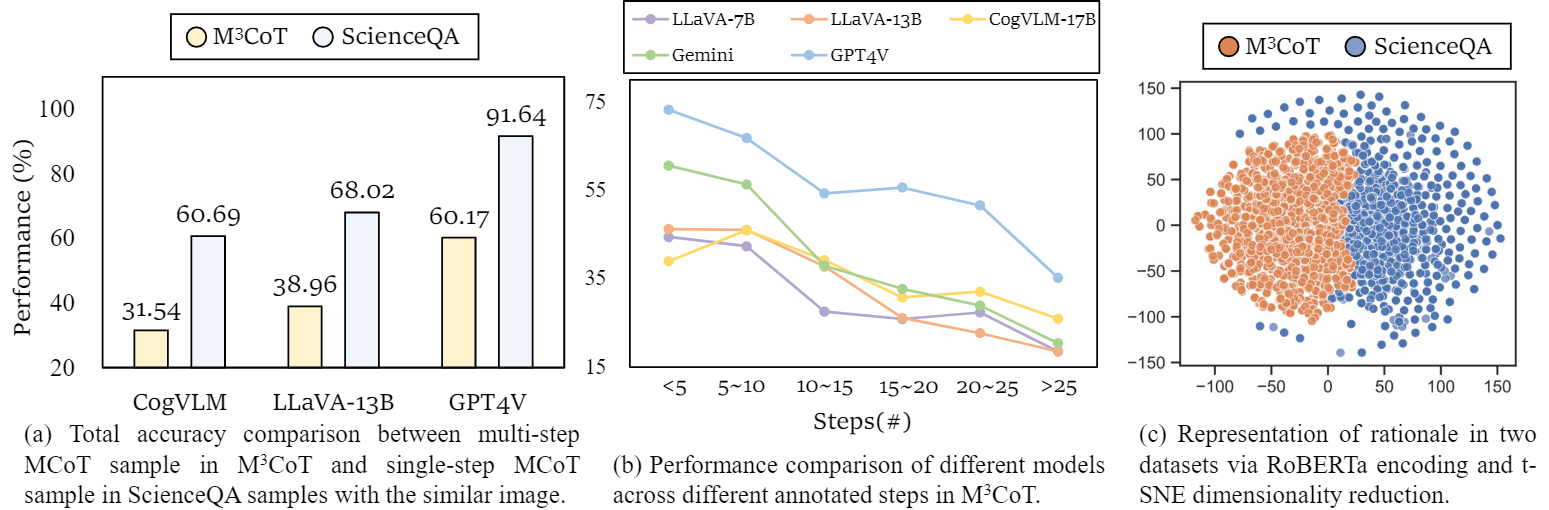
As shown in Figure(a), VLLM has achieved amazing performance in single-step reasoning.
However, compared with single-step MCoT data in ScienceQA, multi-step MCoT data in
M3CoT maintains at least a 29.06% performance decrease (Figure(a)). In order to
further understand the difference in model reasoning with different number of steps, we calculated the
accuracy of different steps. As shown in Figure 7 (b), as the number of reasoning steps increases, the
performance of the model will decrease significantly.
In Figure(c), minimal rationale semantic distribution overlap between datasets further proves that the
multi-step MCoT is an Out-of-Distribution (OOD) problem compared with single-step MCoT. For all, we
attribute the low performance to the multi-step complexities for M3CoT.
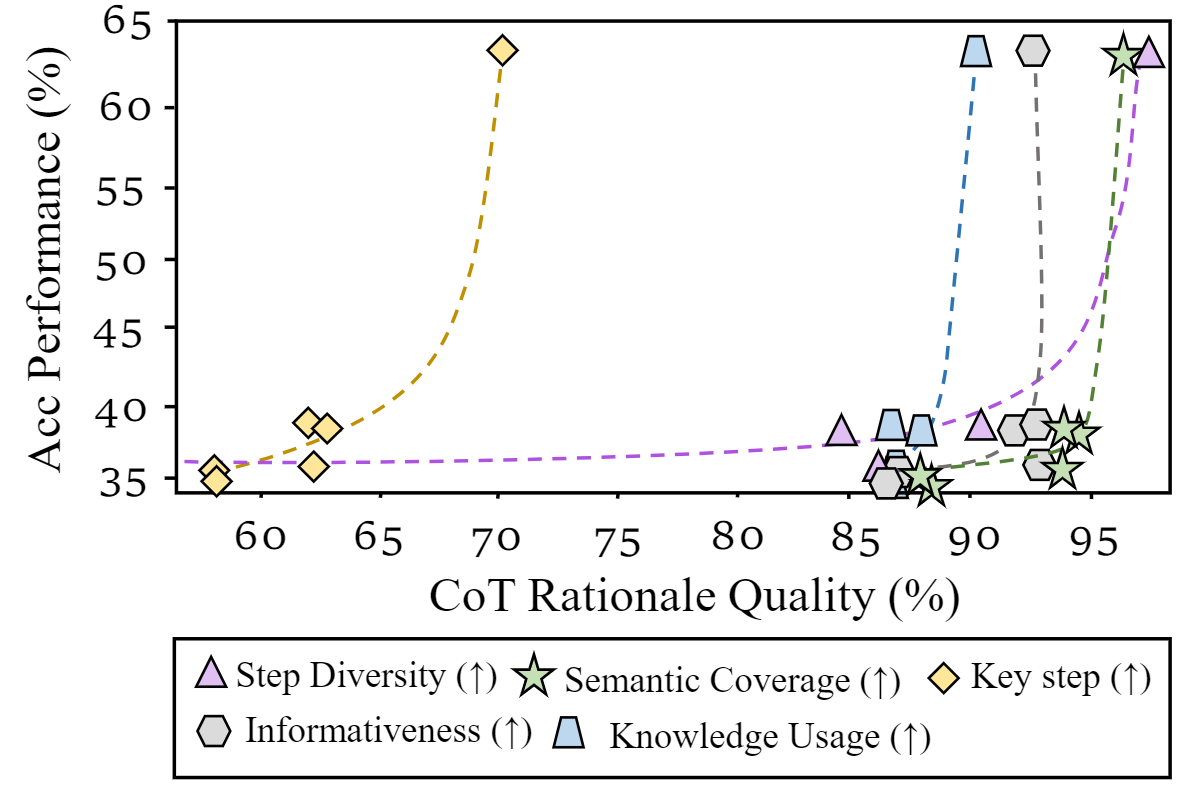
We observe that rationale quality incrementally improves M3CoT performance, while
markedly impacts the accuracy in CoT tasks.
it markedly impacts the accuracy in CoT tasks.
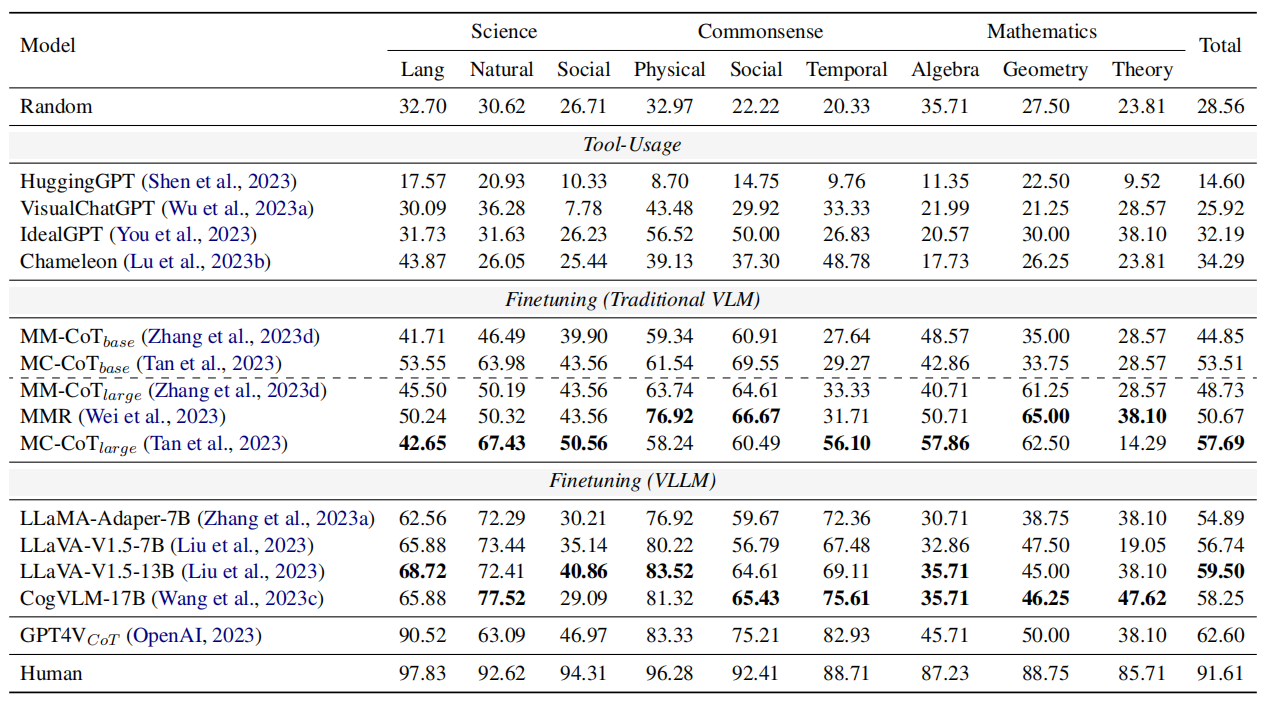
Finetuning on M3CoT can result better performance
@inproceedings{chen-etal-2024-m3cot,
title = "M$^3$CoT: A Novel Benchmark for Multi-Domain Multi-step Multi-modal Chain-of-Thought",
author = "Chen, Qiguang and
Qin, Libo and
Zhang, Jin and
Chen, Zhi and
Xu, Xiao and
Che, Wanxiang",
booktitle = "Proc. of ACL",
year = "2024",
}
Please create Github issues here or email Qiguang Chen , or open up an issue on Github. if you have any questions or suggestions.
This website is adapted from Nerfies and LLaVA-RLHF, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of Qwen-VL and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.